What is Causal Data Fusion?
Posted April 1, 2021 by Paul Hünermund ‐ 5 min read
This post outlines the data fusion process. This automated and do-calculus based inferential engine opens up a complete causal inference pipeline, from problem specification, to identification, to estimation.

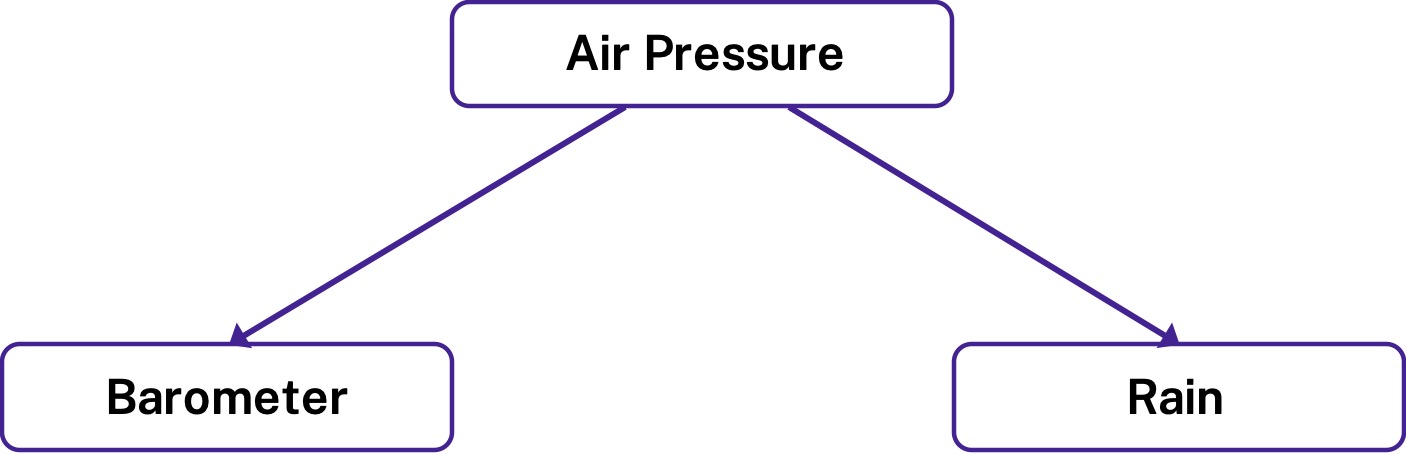
We all know the lore “correlation is not causation”. Just because we observe a stable relationship between two events, such as the reading of a barometer and rain, this does not imply that there is necessarily a causal relationship between the two. Both events are actually caused by a third variable: air pressure. Therefore, we know that if we keep air pressure constant, e.g., by controlling for it in a regression, we will get at the true causal effect of zero.
Causal identification
Let us try to unpack a bit more what we have just done conceptually. We wanted to know the causal effect of the barometer reading on the probability of rain. This is our target query that we would like to estimate from data. Let us further assume that we cannot directly observe this effect. In this example, we could just run a quick experiment, of course. Turn the pointer of the barometer and see whether it has any effect on the likelihood of rain. But in many more realistic settings such an experimental approach is not so easily possible or at least involves much higher costs.
The alternative solution was simple enough though. Conditioning on air pressure will give us the true causal effect of zero – no experiment needed. Based on our domain knowledge that the correlation between the two events might be caused by a third variable, we were able to establish an equivalence between our unobserved target query and another quantity that we actually can observe; i.e., the partial correlation between the barometer reading and rain in a regression. This mapping from an unobservable causal effect to another observable quantity is what we call identification.
Identification as a challenge
Spurious correlation due to confounding by a third variable is not the only challenge that occurs in empirical work though. In the example above, we had to establish a mapping between our causal target query and observational (non-experimental) data. But what if in addition our data also suffers from selection bias, in the sense that it is measured from a non-representative population? Or we have experimental data available, but those experiments do not exactly correspond to the relationships we are interested in? Or perhaps those experiments are conducted in a population that differs slightly from our target population (e.g., in terms of geographic or socio-demographic factors)?
All these circumstances affect the set of quantities that we can compute from our data. As a consequence, they also affect the identification problem described above. Each setting requires a different mapping from our unobservable target query to an expression that is observable to us in that particular situation.
This sounds like a lot of hard work. But luckily there is a causal inference engine available that is powerful enough to deal with all of these cases. This engine is called do-calculus and consists of three syntactic rules that allow us to manipulate causal queries and transform them into other observable expressions. The idea is very similar to the rules of algebra you learned in school to manipulate and solve equations.
But do not worry if you are getting bad memories from high school now. Even though do-calculus has only three simple rules, if you do not like to solve equations with pen and paper, you can simply let a computer do the job for you. Do-calculus transformations are fully automatable with the help of identification algorithms implemented in dedicated causal inference software – similar to computer algebra systems such as Mathematica for equation solving.
The data fusion process
Identification algorithms take three inputs:
- A target query,
- A causal model that captures our domain knowledge of the context under study,
- And the type of data available to us.
As an output, the algorithms return a transformation of the target query that is observable to us given the data, whenever such a solution exists. If the procedure is successful, the analyst can then move over to estimation of the desired causal effect, for example via weighted empirical risk minimization or double/debiased machine learning (to name just a few estimation techniques that have been applied in this context).
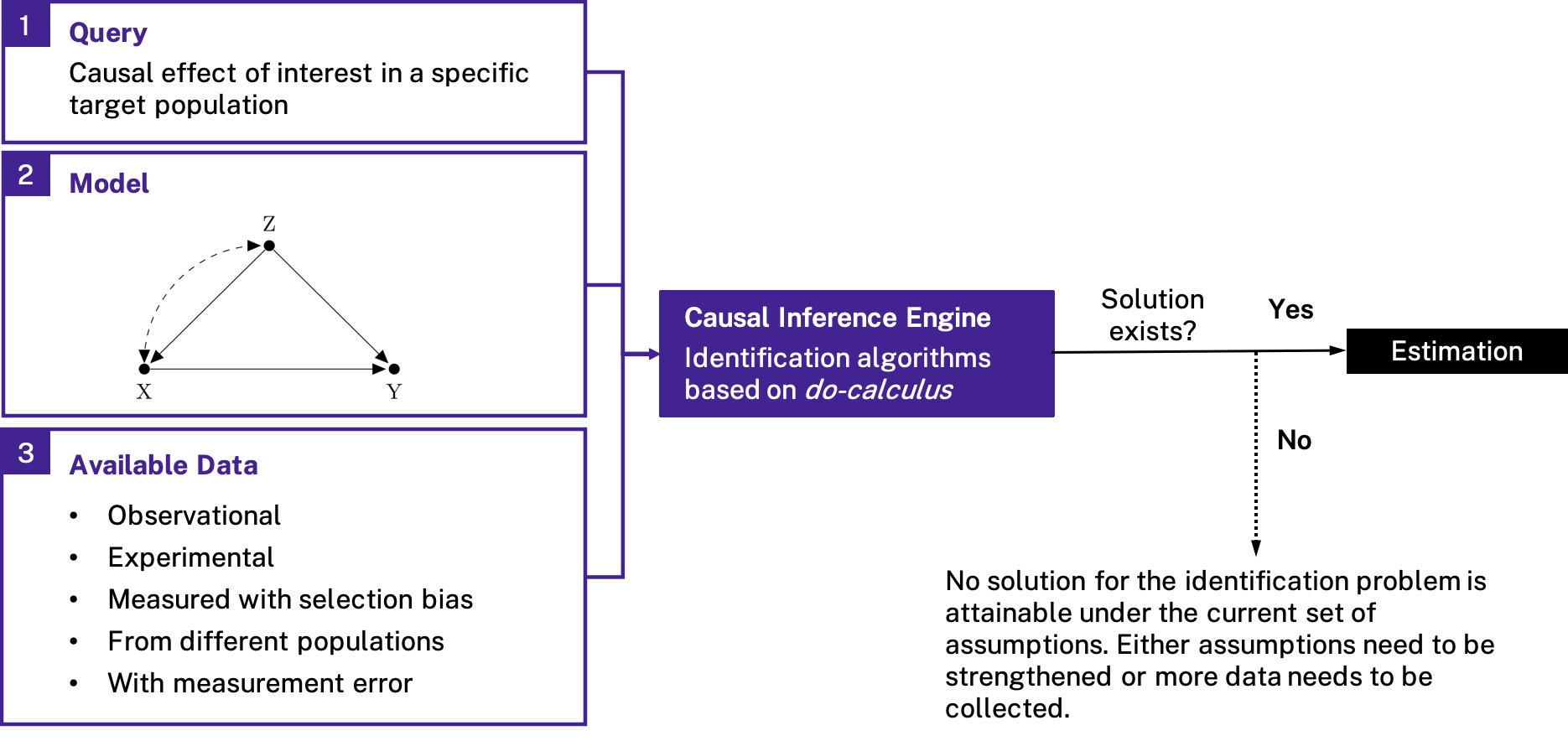
This fully automated inferential engine based on do-calculus opens up a complete causal inference pipeline, from problem specification, to identification, to estimation. The process is called data fusion, based on its ability to incorporate various different data sources to solve thorny causal inference problems. The framework is extremely flexible, so that it can deal with almost all of the empirical challenges researchers encounter in their applied work. No more piecemeal solutions required. At the same time, data fusion is very intuitive to understand. Since everything can be automated, no fancy statistics is needed in order to apply it (you should still understand what is happening under the hood, of course).
This post is meant to be a short introduction into data fusion and its general principles. If you want to learn more about the approach, you can have a look at this paper, which explains its capabilities and the underlying theory in more detail. If you want to learn more about causal data science applications and engage in a dialogue between academia and practice, sign up to our newsletter, which will provide you with regular updates on developments in that space.